mothur Pipeline
mothur is an open source software package for bioinformatics data processing initiated by Patrick Schloss and his development team in the Department of Microbiology and Immunology at the University of Michigan. The mothur project aims to develop a single piece of open source, expandable software to fill the bioinformatics needs of the microbial ecology community. mothur incorporates the functionality of DOTUR, SONS, TreeClimber, s-libshuff and others. Nephele uses mothur v1.46.1.
User Options
Input FASTQ files
The mothur pipeline only operates on paired-end FASTQ data. Additionally, due to resource limitations, the input data size is limited to 10 Gb unzipped or 2 Gb zipped.
Pre-processing
mothur provides a number of commands for sequence processing. These commands allow you to run a fast and flexible sequence analysis pipeline for OTU-based analysis. As an example, the Max length option determines the maximum length of sequences after reads are joined. If you leave the default value of 0, we will infer the correct maximum length from your data. If you wish to override the inferred value, you can set this field to a non-zero value.
- Max length: The default value is 0 (automatically determined).
- Remove sequences that belong to taxa of certain lineages: You can remove taxa that belong to the lineages such as archaea, chloroplast, mitochondria, eukaryote, or unknown. The default lineages are chloroplast, mitochondria, eukaryote, and unknown.
Screen and Pre-Cluster
The Optimize and Criteria settings allow you to set the start and/or end of your aligned sequences. The start and end positions are determined based on the median start and end positions of sequences. The default value will remove any sequence that starts after the position that 90% of the sequences, or ends before the position that 90% of the sequences. This parameter ensures that sequences align to the same region.
- Optimize: default value is start-end.
- Criteris: default value is 90.
The Diffs setting: Maximum difference between sequences in a cluster. Generally, if your sequence length is 200, you might only want to allow up to 2 differences between this sequence and another to be considered noise and be pre-clustered in the same cluster. A diff=2 means that there will be a maximum of 4 differences between the two sequences that are compared which is 2% divergence. If your dataset has longer reads, you can increase the value of this parameter. Learn more here: https://mothur.org/wiki/pre.cluster/
- Diffs: default value is 2.
Analysis
- OTU Picking Reference Database: reference database, default SILVA
- The HOMD database (release 15.1) provides comprehensive curated information on the bacterial species present in the human aerodigestive tract (ADT), which encompasses the upper digestive and upper respiratory tracts, including the oral cavity, pharynx, nasal passages, sinuses and esophagus. HOMD should also serve well for the lower respiratory tract. One important aspect of the HOMD, is that it presents a provisional naming scheme for the currently unnamed taxa, based on the 16S rRNA sequence phylogeny, so that strain, clone and probe data from any laboratory can be directly linked to a stably named reference scheme. The HOMD links sequence data with phenotypic, phylogenetic, clinical and bibliographic information.
- The SILVA database (release 128), on the other hand, is a comprehensive, quality-controlled databases of aligned ribosomal RNA (rRNA) gene sequences from the Bacteria, Archaea and Eukaryota domains. The extensively curated SILVA taxonomy and the new non-redundant SILVA datasets provide an ideal reference for high-throughput classification of data from next-generation sequencing approaches. mothur's SILVA alignment is 50,000 columns long, so it can be compatible with 18S rRNA sequences as well as archaeal 16S rRNA sequences. The developers of mothur have suggested that this is the best reference alignment for the analysis of microbiome.
- Sampling depth for downstream analysis: no default value.
- The sampling depth determines the number of counts for filtering and subsampling the OTU table for downstream analysis. Samples which have counts below this value will be removed from the downstream analysis. The counts of the remaining samples will be subsampled to this value. If not specified, it will be calculated automatically (see FAQ).
Pipeline Major Steps
Join forward and reverse short reads as contigs
Contigs are generated using the command make.contigs, and then renamed using the command
rename.seqs in order to reduce the memory usage. The make.contigs command extracts
the sequence and quality score data from the FASTQ files, creates the reverse complement of the reverse read
and then joins the reads into contigs. This command implements a simple algorithm. Briefly, the algorithm
first aligns the pairs of sequences, and then searches across the alignment and identifies any positions
where the two reads disagree. If one sequence has a base and the other has a gap, the quality score of the
base must be over 25 to be considered real. If both sequences have a base at that position, then one of the
bases is required to have a quality score 6 or higher than the other. If it is less than 6 points, then the
consensus bases is set to an N. mothur only supports samples with pair-end reads.
Screen contigs to reduce sequencing errors
This step utilizes the commands screen.seqs. Specifically, the screen.seqs command
preserves sequences that satisfies certain criteria. Several parameters are used to specify the criteria. In
the Nephele's mothur pipeline, 10% of sequences are randomly selected to estimate optimal values for these
parameters. The mothur commands summary.seqs is used to estimate the parameters
start and end, and a custom algorithm maxlength.
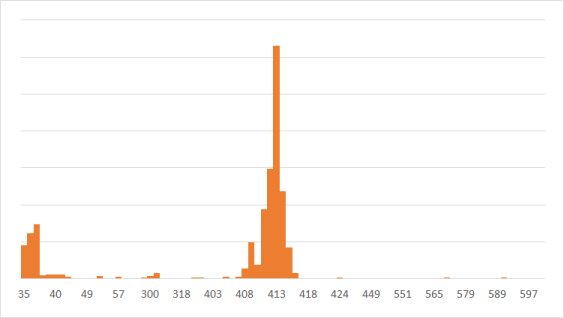
startandend: remove sequences that do not start and end at given positions based on the alignment. It is common that some sequences do not align in the same region as most of others. These sequences likely are PCR artifacts or came from the contamination in samples. Thestartandendpositions are determined based on the median start and end positions of sequences. The median start and end positions are generated from the commandsummary.seqs.maxlength: remove sequences that exceed a certain length, default 0. Note: this value will be determined automatically based on the summary statistics of sequence lengths, if it is set to 0. It is recommended not to set this value manually.
The maxlength largely works as quality assurance on the sequences. This option removes sequences
that are either too long or too short. Excessive long sequences are likely due to incorrect pairing while
short sequences indicate low quality reads. This parameter, however, is generally difficult to determine
precisely because it depends on the 16S region and PCR primers being used. The Nephele's mothur pipeline
includes a custom algorithm that automatically determines most probable length. The algorithm constructs a
histogram based on the sequence lengths and determine the most appropriate cutoff for analysis. The
algorithm, although rudimentary, seems relative robust.
 |
Dereplicate sequences
This step returns only the unique sequences and reduces the computing time in the downstream analysis. The
unique.seqs command returns the unique sequences found in a FASTA-formatted sequence file and a
file that indicates those sequences that are identical to the reference sequences. Often times a collection
of sequences will have a significant number of identical sequences. It consumes considersable processing
time and have to align, calculate distances, and cluster each of these sequences individually. This command
significantly reduces processing time by eliminating and recording duplicate sequences.
Taxonomic assignment
This step utilizes the command align.seqs. This command aligns a user-supplied FASTA-formatted
candidate sequence file to a user-supplied FASTA-formatted template alignment. Taxonomic assignments in the
reference database are then assigned to the OTUs. The reads that failed to align to the reference sequences
are clustered against one another without an external reference sequences. This approach, de novo
OTU picking, is particularly useful for studying populations where there is poor characterization of
existing data. The mothur pipeline currently aligns sequences to either the HOMD or mothur's SILVA v128
databases.
Filter sequences
This step removes columns from alignments based on given criteria with the command filter.seqs.
Alignments generated against reference alignments, such as HOMD or SILVA, often have columns where every
character is either a .
or a -
. These columns are not included in calculating distances
because they have no information in them. By removing these columns, the calculation of a large number of
distances is accelerated.
Remove sequences due to sequencing errors
This step remove sequences that are likely due to sequencing errors with the command
pre.cluster. This command implements a pseudo-single linkage algorithm originally developed by
Sue
Huse. The basic idea is that abundant sequences are more likely to
generate erroneous sequences than rare sequences. The algorithm proceeds by ranking sequences in order of
their abundance. It then walks through the list of sequences looking for rarer sequences that are within
some threshold of the original sequences. Those that are within the threshold are merged with the larger
sequence. The original Huse method performs this task on a distance matrix, whereas mothur performs the same
task based on the original sequences. The advantage is that the algorithm works on aligned sequences instead
of a distance matrix. This is advantageous because pre-clustering removes a large number of sequences, which
makes the distance calculation much faster.
Remove chimeric sequences
The command chimera.vsearch reads a FASTA file and reference file, and outputs potentially
chimeric sequences. This command utilizes the VSEARCH program. VSEARCH stands for vectorized search, as the tool takes
advantage of parallelism in the form of SIMD vectorization as well as multiple threads to perform accurate
alignments at high speed. VSEARCH uses an optimal global aligner (full dynamic programming Needleman-Wunsch), in contrast to USEARCH which by
default uses a heuristic seed and extend aligner. This usually results in more accurate alignments and
overall improved sensitivity (recall) with VSEARCH, especially for alignments with gaps. The VSEARCH program
supports de novo and reference based chimera detection, clustering, full-length and prefix
dereplication, rereplication, reverse complementation, masking, all-vs-all pairwise global alignment, exact
and global alignment searching, shuffling, subsampling and sorting. It also supports FASTQ file analysis,
filtering, conversion and merging of paired-end reads.
Cluster OTUs
Sequences are clustered into OTUs using cluster.split. cluster.split first computes the
pairwise distances between sequences and saves them to a distance matrix. Nephele checks the size of this
distance matrix to ensure it will fit in memory (see this FAQ) before the clustering takes
place.
Classify OTUs
This step generates a consensus taxonomy for an OTU. From each OTU, a single sequence is selected as a
representative. This representative sequence is annotated, and that annotation is applied to all remaining
sequences within that OTU. The command classify.otu requires parameters such as list, taxonomy,
count, cutoff, label and probabilities. The default is the Wang
method. The Wang method looks at all taxonomies represented in the
template, and calculates the probability a sequence from a given taxonomy would contain a specific
kmer. Then calculates the probability a query sequence would be in a given taxonomy based on the
kmers it contains, and assign the query sequence to the taxonomy with the highest probability. This
method also runs a bootstrapping algorithm to find the confidence limit of the assignment by randomly
choosing with replacement 1/8 of the kmers in the query and then finding the taxonomy.
Remove sequences of certain lineages
The remove.lineage command reads a taxonomy file and a taxon and generates a new file that
contains only the sequences not containing that taxon. The default option is to remove the lineages
chloroplast, mitochondria, eukaryote, and unknown.
Fast distance-based phylogenetic tree
This step generates a distance-based phylogenetic tree based on the relaxed neighbor joining (RNJ) algorithm
with the command clearcut. RNJ modifies the traditional neighbor joining algorithm and achieves
typical asymptotic runtime of O(n2logN) without a significant reduction in the
quality of the inferred trees. As with traditional neighbor joining, RNJ will reconstruct the true tree
given a set of additive distances. Relaxed neighbor joining was developed by Jason Evans, Luke Sheneman, and
James Foster from the Initiative for Bioinformatics and Evolutionary STudies (IBEST) at the
University of Idaho. No custom parameters are available.
Output Files/Folders
combo.*.biom: BIOM file of sequence variant counts with taxonomic assignment at the genus level.combo.*.phylip.dist: Phylogenetic distance calculated using the commandsdist.seqsusing all unique sequences from pre-clustering.combo.*.fasta: The final FASTA file for taxonomic assignment after a series of quality control steps.combo.*.opti_mcc.*: Consensus taxonomy and summmary with the optimal Matthews correlation coefficient (mcc) value.otu_summary_table.txt: Summary of the numbers of taxonomically assigned reads for each sample in the dataset.rep-seqs.fasta: File containing sequences that correspond to each OTU identified after clustering at 0.03 identity. This file can be used as input to the PICRUSt pipeline along with the biom file.rep-seqs-unrooted-tree.nwk: This tree file is produced after calculating distances between the OTU representative sequences and generating a neighbor joining tree. This can be used for further analysis with tools such as phyloseq.rep-seqs-rooted-tree.nwk: This file is derived from the rep-seqs-unrooted-tree.nwk but it is now rooted. This file can be used as input to the Downstream Analysis pipeline along with the biom file.- graphs: Output of our visualization pipeline using plotly and morpheus. See visualization pipeline page for more information on the output files.
Tools and References
- PD Schloss, SL Westcott, T Ryabin, JR Hall, M Hartmann, EB Hollister, RA Lesniewski, BB Oakley, DH Parks, CJ Robinson, JW Sahl, B Stres, GG Thallinger11, DJ Van Horn and CF Weber (2009) Introducing mothur: Open-Source, Platform-Independent, Community-Supported Software for Describing and Comparing Microbial Communities, doi: 10.1128/AEM.01541-09.
- MGI Langille, J Zaneveld, JG Caporaso, D McDonald, D Knights, JA Reyes, JC Clemente, DE Burkepile, RL Vega Thurber, R Knight, RG Beiko and C Huttenhower (2013) Predictive functional profiling of microbial communities using 16S rRNA marker gene sequences. Nature Biotechnology, doi: 10.1038/nbt.2676.
- J Evans, L Sheneman, and JA Foster. Relaxed neighbor-joining: a fast distance-based phylogenetic tree construction method, Journal of Molecular Evolution, 62:785-792.